

Après s’être initié aux bases du codage avec Javascript côté front, la suite logique était le Php pour le back-end. Et qui dit back, dit base de données. MySQL, en l’occurence.
I’ll BE BACK
La découverte du Php a été un sacré pas en avant pour moi. Je pense que les possibilités qu’il offre en terme de dynamisme sont très exaltantes pour un débutant. De plus, le fonctionnement des bases de données et l’apprentissage du langage SQL de base reste très accessible, pour peu que l’on soit suffisamment motivé.
À l’aide de tutos sur internet et du formateur, j’ai très rapidement pu mettre en place un chat simple et fonctionnel, en partant de rien. Certes, les fonctionnalités, si l’on peut appeler ça comme ça à ce niveau, restaient très basique, mais voir son propre programme fonctionner sans accroc est très enthousiasmant.
Par la suite, un blog a été réalisé, qui connaîtra pas mal d’évolutions, pour finalement être mis en ligne.
Un peu de code ?
Et bien oui, mais pas trop.
On va pas non plus perdre du temps à coller 150 screenshots de code pas vraiment exceptionnel, on l’a déjà fait avec le CSS.
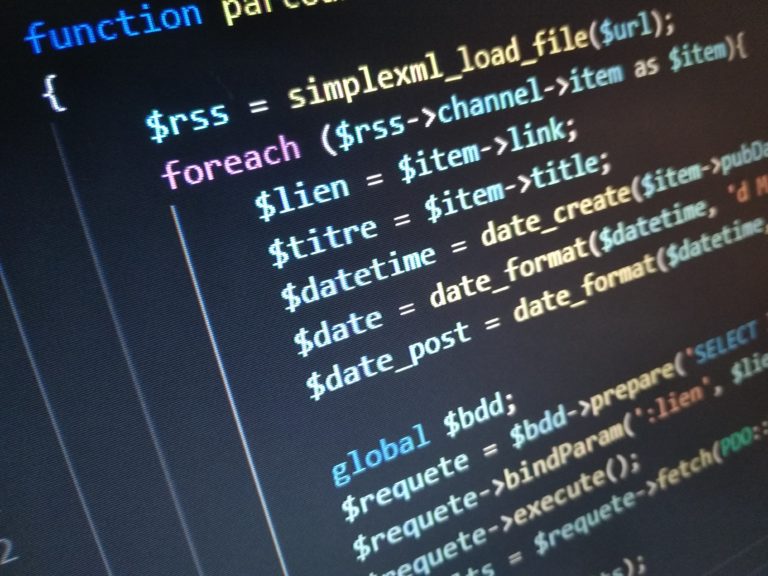
Non, juste un simple exemple : celui du script principal (je veux dire par là le plus important) de C-MON.
Récupération des flux rss
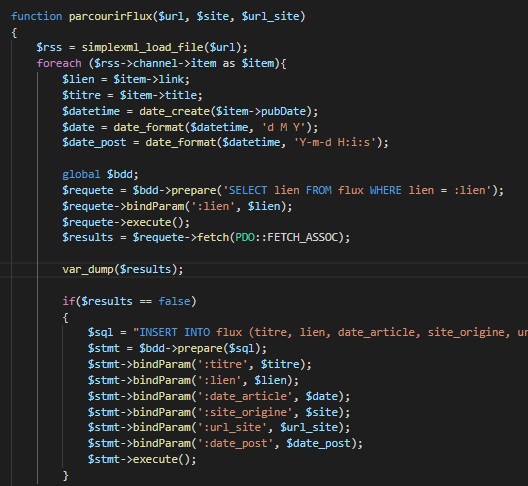
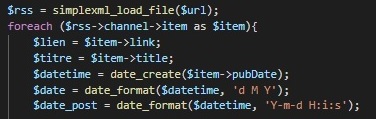
Il s’agit d’une fonction php, simplexml_load_file(), permettant de récupérer les informations d’une page de flux rss, prenant en paramètre l’url de la page en question.
Elle est ici incluse dans une autre fonction faite maison, génialement nommée parcourirFlux(), qui elle prend en paramètre l’url de la page de flux rss, le nom du site ciblé et l’url de sa page d’accueil. Ça permet ainsi de cibler plusieurs sites internet sans se retaper 50 lignes de code (le principe même d’une fonction).
Au final, simplexml_load_file() crée un tableau pour chaque lien, que l’on parcours pour y récupérer les informations qui nous intéressent. Dans le cas présent, je me suis contenté de ce qui m’intéressait le plus et que l’on est sûr d’avoir à chaque fois, à savoir le lien, le titre et la date de publication.
Ensuite, à l’aide d’une requête SQL, on parcourt la base de données pour comparer le lien traité à ceux déjà enregistrés. La fonction var_dump() n’est là que pour vérifier que tout se passe bien lors d’un lancement manuel du script.

Lorsqu’il n’y a aucun résultat ($results == false), c’est que le lien n’a pas encore été ajouté à la base de donnée. On a donc une nouvelle requête SQL, cette fois pour insérer une nouvelle ligne dans la table, contenant toutes les infos précédemment récupérées.
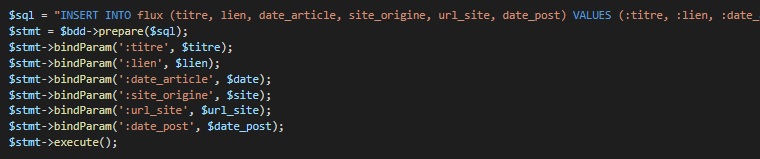
Sélection des sites et affichage
Bon tout ça c’est bien beau, mais où qu’on les met, les sites ?
Ben dans un autre fichier, comme ça on touche plus à celui de la fonction : on se contente de l’appeler lui une seule fois (maj_function.php) et sa fonction pour chaque site ciblé.
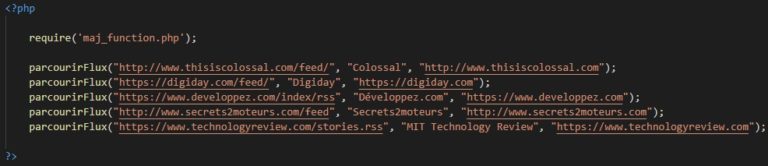
Alors voilà… Mais oups, n’aurait-on pas oublié un truc ? Quand le fichier se lance, ça parcours les différentes pages de flux rss, ça met à jour la base de données si besoin, mais le script, lui, qui le lance ?
C’est le point négatif de cette méthode… Un script php ne peut pas s’automatiser tout seul : il faut donc faire une requête « cron » sur le serveur (pour les courageux qui bossent sur des serveurs dédiés) ou tout simplement une tâche planifiée chez votre hébergeur (plus simple et ils en proposent tous 😉 ).
Personnellement, mon hébergeur me permet d’automatiser très facilement ce script pour un lancement toutes les 15 minutes, et c’est déjà pas mal. Cela permet d’actualiser assez rapidement le flux d’information, ajoutant chaque nouvel article d’un site à la liste.
Enfin, pour afficher les résultats, il suffit d’aller récupérer les données avec une requête SQL, et on affiche les résultats comme on veut et où on a envie. Elle est pas belle, la vie ?
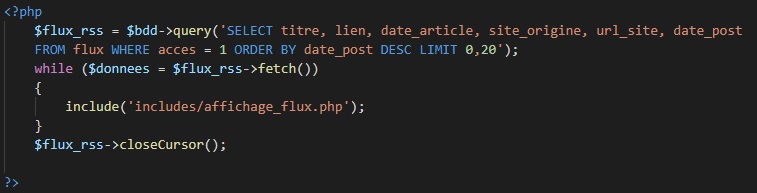
L’include appelle un petit bout de code en php/html. Couplé à des classes CSS, il affiche les liens à ma convenance.

Et ensuite ?
La suite du programme sera d’abord d’approfondir le modèle MVC. Bien que les fichiers de ZeBlog soient séparés selon leur fonction, traitement ou affichage, on est encore loin d’un véritable modèle-vue-contrôleur.
De plus, adopter le MVC permettra de mieux se préparer à passer à la POO, programmation orientée objet, qui est en train de devenir un standard chez les développeurs. Pour l’instant, je n’ai fait que survoler la POO en javascript, avec les cours d’Openclassrooms.
Quelques classes, deux-trois objets et hop, on s’y croît très vite !
Mais bon, tout ça, ce sera pour après la formation !